
Due to its agility, Python is now the world’s most popular coding language. Enterprises have witnessed an exponential growth of the number of lines written in Python to develop a wide range of critical applications. Artificial intelligence, data science, analytics, and machine learning processes are now heavily dependent on Python with its extensive libraries.
However, this soaring popularity of Python is a double-edged sword. While it boosts productivity and accelerates innovation, it also presents a challenge for data management and governance. Is your data lineage broken due to the inability to handle the fast growing number of Python frameworks? Does your glossary cover Python assets? How do you establish policies and rules regarding Python assets? How do you find out which code is duplicated?…
Orion’s Enterprise Information Intelligence Graph (EIIG), a self-defined data fabric, is built to address these challenges.
Automation, automation, and automation
The footprint of Python code within enterprises is continuously and rapidly growing. The large and ever growing number of Python frameworks make it impossible to incorporate a manual process of validating coding standards and checking for correctness. EIIG offers dedicated ingestors for more than 60 technologies including Python. With EIIG, customers can automatically ingest metadata from Python scripts, and weave it into a knowledge graph. In this knowledge graph, column-level data lineage is automatically visualized. EIIG also automatically maps these Python assets with business terms, as a part of its enterprise data catalog.
EIIG’s automation enables enterprise customers to fully understand and visualize the flows of information, including Python assets, without the need to hire a team of consultants.
With potentially millions of lines of Python code, it’s important to gain oversight of what’s in the code. As the adage goes “A picture is worth a thousand words.” In our case the lineage flow presented in EIIG is worth tens of thousands of lines of code.
Insight, insight, and insight
Transparency of Python frameworks and traceability of Python assets in relation with other systems build the foundation for getting value out of your data efficiently.
Take ETL for example. Python is increasingly used as a low-cost/agile replacement for the traditional ETL tools. When you have no ability to parse Python scripts, ETL pipelines become black holes or broken links in your enterprise data landscape. With EIIG, there are no more black holes. You now have total visibility into ETL jobs written in Python frameworks like Pandas or Airflow. You can see how data transfers between systems, flows from the source through ETL to a data warehouse such as Snowflake or AWS RedShift and ends up in a BI report such as Tableau, Qlik, or PowerBI.
What is more, EIIG can show quality and trustworthiness of data assets at every stage of the data workflows including Python ETL jobs. This capability helps quickly identify the root cause of issues in near real time. It also enables accurate and efficient data analytics.
Different data consumers now can leverage EIIG to help them with Python assets. Data stewards can easily set up and enforce policies and rules using the knowledge graph. Data governance and compliance team members can visually show the auditors the traceability of all information assets including Python. They can also apply regulatory policies against compliance glossaries such as those for GDPR, CCPA, BCBS 239 and HIPAA. Data privacy managers can click and tag all PII assets in the Python environment.
Python is the most dominant data science programming language. EIIG seamlessly connects the dataframes produced by Python with legacy assets, allowing for near-real time impact analysis, data trust propagation and duplication detection. Understanding the quality of the Python assets, data scientists can choose the most relevant data sets without the need to figure it out on their own. EIIG also facilitates collaboration between team members since they have transparency of what everybody else is working on.
Accelerate Application Modernization/Cloud migration projects
Last but not the least, EIIG accelerates the implementation of migration/modernization projects. Metadata analytics in EIIG provides insights into key metrics such as popularity, value and quality (data and code) of python assets. In the knowledge graph, users can see what code or ETL jobs are duplicated. With this insight, they can decide what assets to reuse and what assets to be deleted quickly and accurately, thus saving time and other valuable resources. EIIG’s powerful real-time impact analysis incorporating Python assets offers more comprehensive intelligence and enables process dependency tracking and data change capturing. By prioritizing based on the evidence of data assets, customers can ensure that their migration project is on time and on budget.
In summary, EIIG’s comprehensive support of Python in its self-defined fabric provides enterprises with tangible benefits by minimizing human intervention, enabling more accurate and timely business decisions, and cutting costs at the same time.
About the author: Niu Bai, Ph.D. is the Head of Global Business Development and Partnerships at Orion Governance, Inc.
recent posts

How Orion Governance’s Enterprise Information Intelligence Graph Enhances AI Explainability
As organizations accelerate AI adoption, a critical barrier limits trust in AI outcomes: the inability to clearly track where [...]
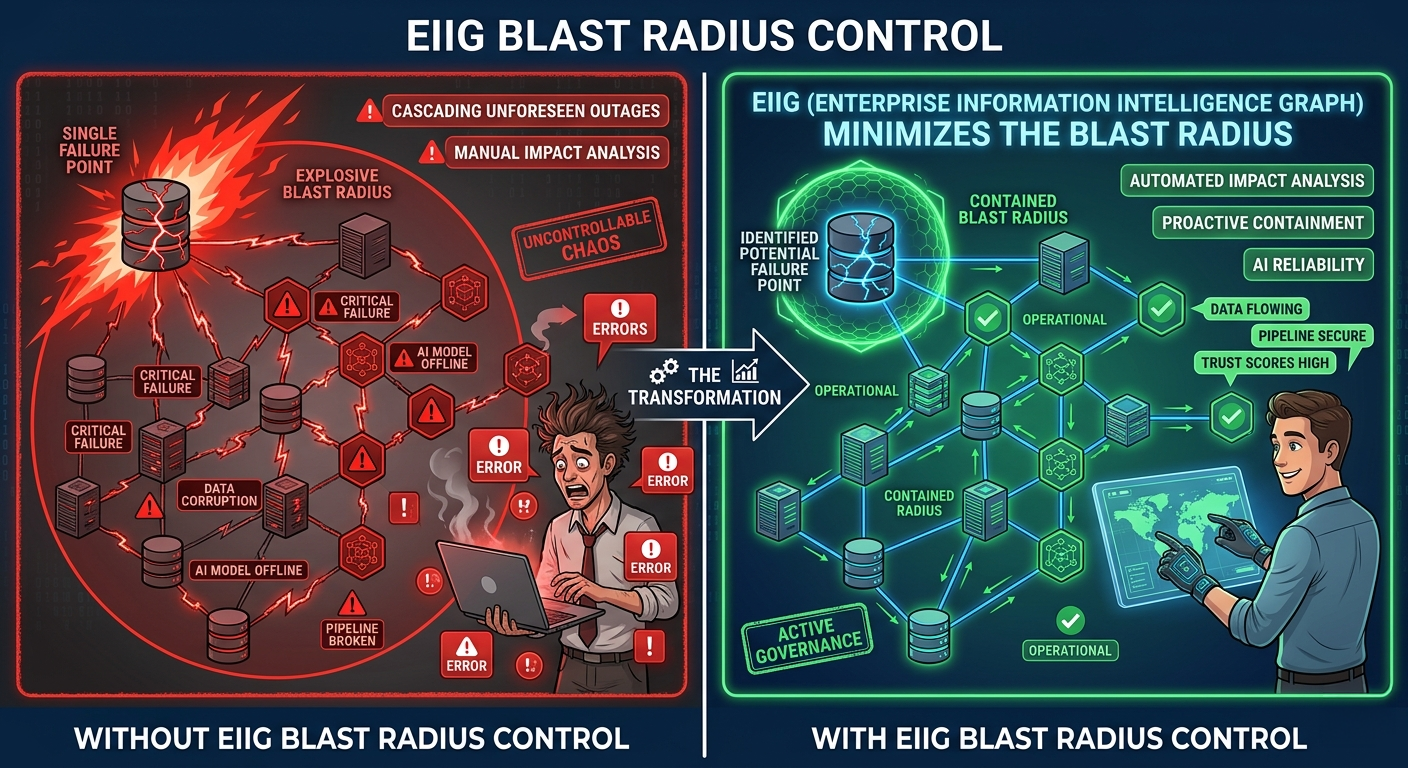
How Orion Governance’s EIIG Enables Blast Radius Calculation to Strengthen Data and AI Governance
In modern enterprises, data ecosystems have become deeply interconnected across cloud platforms, AI pipelines, analytics tools, legacy systems, and [...]
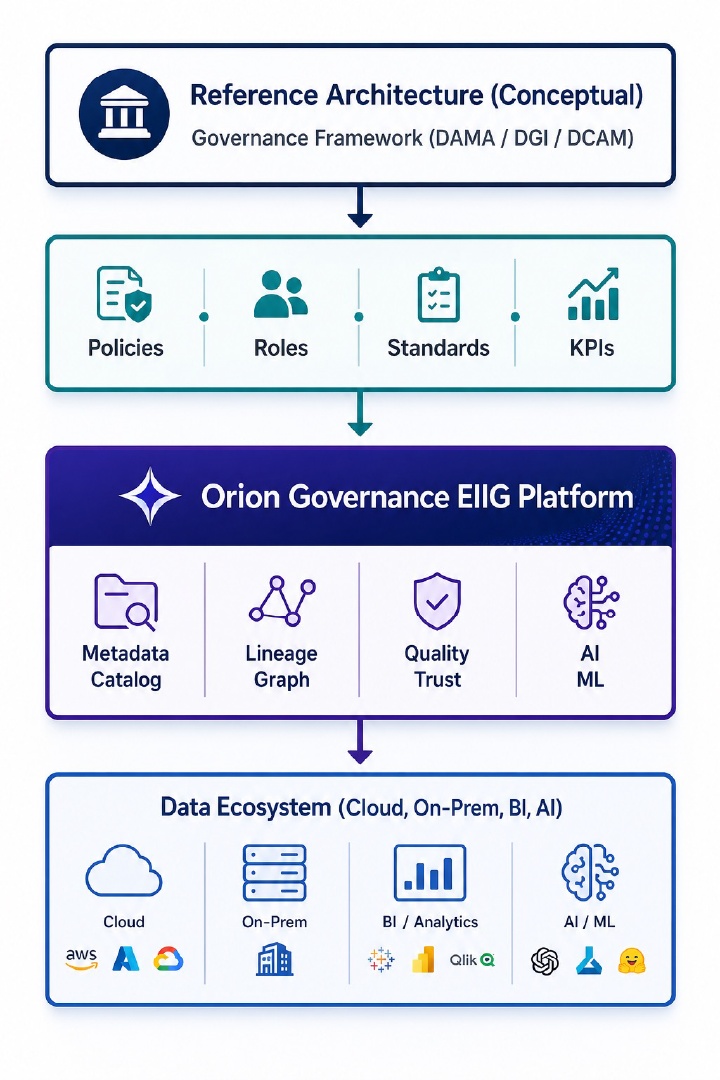
How to Leverage Orion Governance Enterprise Information Intelligence Graph to Implement Data Governance Framework
To use Orion Governance Enterprise Information Intelligence Graph (EIIG) effectively, you shouldn’t treat it as “just a tool.” It [...]

Orion Governance Enterprise Information Intelligence Graph Data Quality Baseline Report
A Data Quality (DQ) Baseline Report acts as the "health check" of your data before any remediation begins. In [...]

From Data Lineage to Enterprise Intelligence Fabric
Orion Governance’s Enterprise Information Intelligence Graph (EIIG) offers the definitive data lineage solution: automated, comprehensive, granular, multi-layered, and collaborative. [...]

The Benefits of Using Orion Enterprise Information Intelligence Graph to Accelerate Cloud Migration/ Modernization
Cloud migrations are often framed as a technical exercise — move systems, modernize platforms, decommission legacy tools. But the [...]
