
In the age of Big Data, the importance of understanding the data we work with has become paramount. The sheer volume, velocity, and variety of data enterprise teams encounter daily necessitates tools and techniques to ensure its quality, consistency, and relevance. One of the key processes employed to achieve this understanding is data profiling. In this blog, we delve deep into what data profiling is, its significance, and the techniques involved.
Understanding Data Profiling
At its core, data profiling is the systematic process of inspecting, describing, and analyzing a data source to derive meaningful insights about its content, structure, and quality. This is done with the aim of understanding the data’s intricacies, discovering any inconsistencies or anomalies, and making informed decisions about its usability for a given purpose.
Significance of Data Profiling
Quality Assurance: By profiling data, organizations can uncover inaccuracies, inconsistencies, or missing values in their datasets. Detecting such anomalies early can save valuable resources and effort in downstream processes, ensuring that only clean, reliable data is used in decision-making processes.
Data Governance: Establishing a solid foundation for data governance begins with understanding the data in hand. Data profiling provides the necessary insights for creating rules, policies, and standards that guide the handling and use of data within an organization.
Integration & Migration: Before integrating new data into an existing system or migrating data to a new platform, understanding the nature and structure of that data is crucial. Data profiling aids in identifying any potential compatibility issues or transformations that might be required.
Metadata Management: Metadata, the data about data, is crucial for maintaining a comprehensive view of an organization’s data landscape. Data profiling helps in extracting, managing, and maintaining this metadata.
Key Techniques in Data Profiling
Column Profiling: This is the examination of individual columns or attributes in a dataset. Here, analysts derive statistics like minimum, maximum, average, median, mode, count of unique values, count of null values, and data type distributions. It helps understand the nature and distribution of data in a particular attribute.
Dependency Profiling: This aims to discover dependencies between columns. For example, in a dataset with columns ‘City’ and ‘Country’, it might be observed that every time ‘Paris’ appears in the ‘City’ column, ‘France’ appears in the ‘Country’ column, indicating a functional dependency.
Redundancy Profiling: Here, the focus is on finding duplicated data across the dataset. Redundant data can lead to skewed analytics and needs to be addressed before any analytical operation.
Pattern Profiling: It involves identifying and analyzing recurring patterns in data values, such as formats in telephone numbers or email addresses. Recognizing these patterns can highlight inconsistencies and guide validation rules.
Outlier Detection: In this method, values that deviate significantly from other values in the dataset are identified. Outliers can either be errors or genuine exceptions, but in either case, they require further examination.
Tools & Technologies
There’s a myriad of tools available for data profiling, ranging from open-source solutions to enterprise-grade software. These tools often come equipped with features for automation, visualization, and collaboration, making the process of data profiling smoother and more integrated.
Challenges in Data Profiling
While data profiling offers numerous benefits, it is not without challenges:
Volume: As data volumes grow exponentially, profiling large datasets can be computationally intensive and time-consuming.
Complexity: Datasets can be multi-dimensional, with nested structures and varied formats. Profiling such data requires advanced tools and expertise.
Privacy Concerns: Profiling can sometimes lead to the revelation of sensitive information, making it essential to implement robust data masking or anonymization techniques.
Finding A Data Profiling Solution
In the contemporary data-driven landscape, the saying “garbage in, garbage out” holds undeniable truth. Data profiling, thus, emerges as a fundamental step in the data management pipeline, ensuring that organizations are basing their decisions on accurate, consistent, and high-quality data. As the complexity and volume of data continue to rise, the techniques and tools for data profiling will only evolve, making it an indispensable discipline in the world of data analytics.
Enterprises across industries are searching for the right data profiling solution for them. Orion Governance’s Enterprise Information Intelligence Graph (EIIG) is an all-in-one platform with a wide range of capabilities including data governance, data lineage, data catalog, augmented data quality, active metadata analytics, and near real-time impact analysis and similarity analysis. Learn more about EIIG and how it can help your enterprise overcome challenges in data profiling and more.
More data profiling resources:
recent posts

How Orion Governance’s Enterprise Information Intelligence Graph Enhances AI Explainability
As organizations accelerate AI adoption, a critical barrier limits trust in AI outcomes: the inability to clearly track where [...]
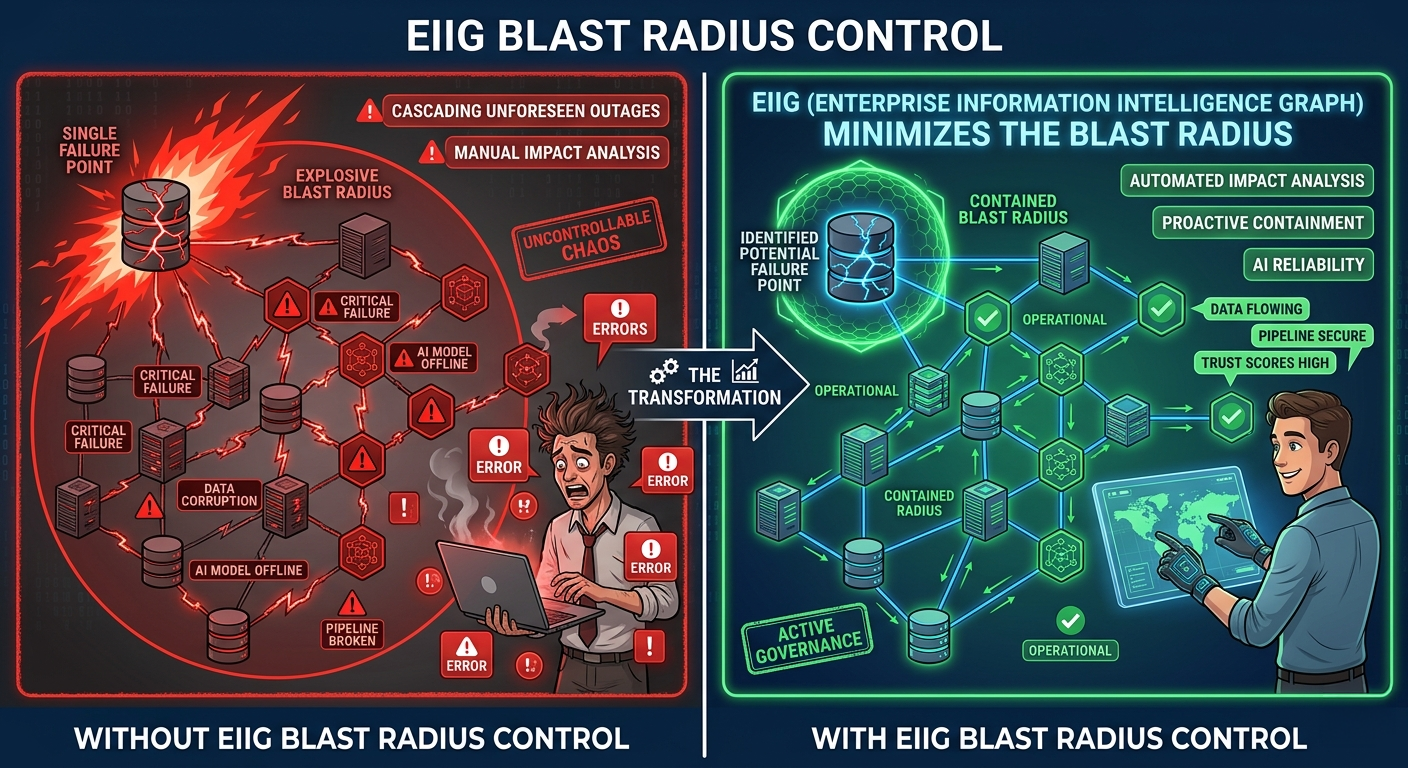
How Orion Governance’s EIIG Enables Blast Radius Calculation to Strengthen Data and AI Governance
In modern enterprises, data ecosystems have become deeply interconnected across cloud platforms, AI pipelines, analytics tools, legacy systems, and [...]
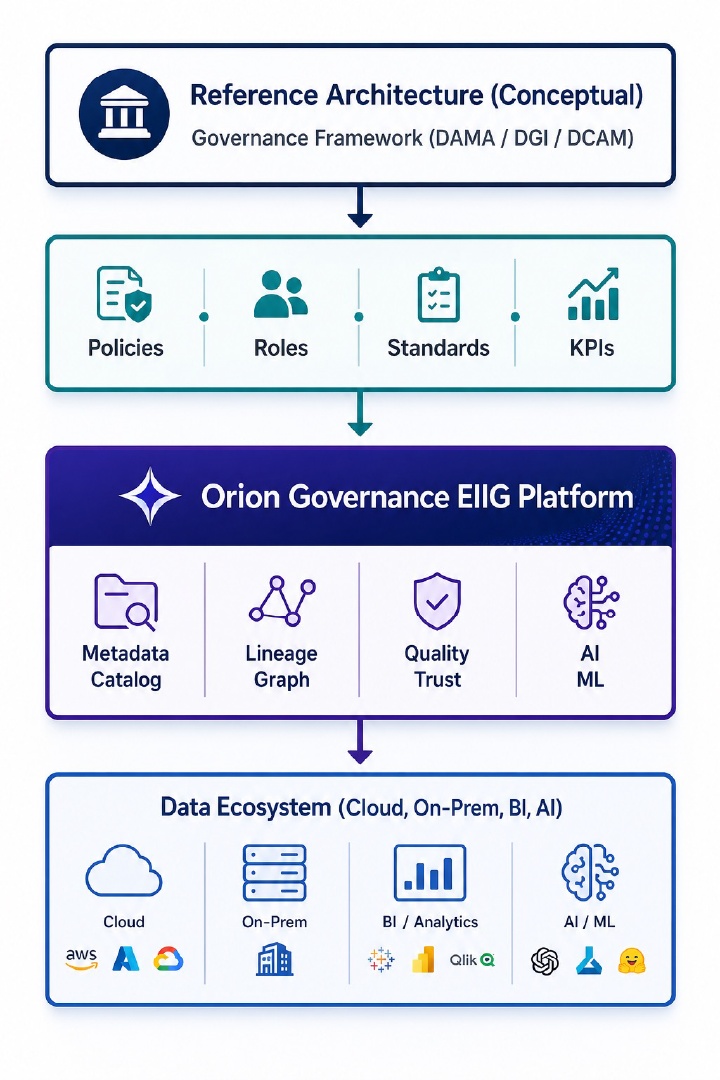
How to Leverage Orion Governance Enterprise Information Intelligence Graph to Implement Data Governance Framework
To use Orion Governance Enterprise Information Intelligence Graph (EIIG) effectively, you shouldn’t treat it as “just a tool.” It [...]

Orion Governance Enterprise Information Intelligence Graph Data Quality Baseline Report
A Data Quality (DQ) Baseline Report acts as the "health check" of your data before any remediation begins. In [...]

From Data Lineage to Enterprise Intelligence Fabric
Orion Governance’s Enterprise Information Intelligence Graph (EIIG) offers the definitive data lineage solution: automated, comprehensive, granular, multi-layered, and collaborative. [...]

The Benefits of Using Orion Enterprise Information Intelligence Graph to Accelerate Cloud Migration/ Modernization
Cloud migrations are often framed as a technical exercise — move systems, modernize platforms, decommission legacy tools. But the [...]
