
What are some of the key challenges in implementing an enterprise data catalog? Check out this list of challenges that your enterprise may face when implementing a data catalog.
- The scope of metadata within the catalog
- Only a small portion of system data is transferred to the data lake or data warehouse for analytics, and even within that limited portion, only a fraction is accessible for analysis.
- The lack of connectors for legacy technologies hampers the availability of source metadata.
- Data lake vendors’ technical metadata repositories are unable to capture metadata beyond their own framework.
- Variety of data storage formats and tools
- Organizations possess a wide range of intricate methods for data storage. The existing catalogs lack the capability to offer comprehensive and in-depth integrations required for conducting impact analysis utilizing metadata.
- Metadata curation
- Catalogs can harvest massive amounts of metadata but without proper semantics, descriptions, categorization, and classification it can be very difficult to find and use relevant data.
- Catalog contains data from all kinds of domains that have sensitive information. Therefore, without proper safeguards, there are increased risks of unauthorized access, leakage, and breach.
- The continuous expansion of metadata across various domains and business areas poses significant challenges in terms of managing redundant data, ensuring metadata quality, and identifying subject matter experts (SMEs) for effective curation. Regardless of the catalog sophistication, be it a comprehensive system or a basic spreadsheet, addressing these challenges remains a formidable task.
- Responsibility assignment
- To effectively execute a data catalog, enterprises must initially establish clear roles, responsibilities, and procedures. Subsequently, they should allocate appropriate responsibilities to the corresponding roles and link those roles with the organization’s job descriptions. This approach guarantees that the catalog implementation aligns with business requirements and ensures the reliability, security, and compliance of the data.
- Different business areas may have different responsibilities for similar data in different contexts and catalogs lack the ability to support complex/matrix responsibility assignments.
- Hidden transformation
- Data transformations are not only concealed within ETL processes but also within programming languages such as Python, Scala, and Java. Unfortunately, many catalogs lack the ability to reveal these transformations in detail, making it difficult to assess their impact and understand the exact changes made to the data before it is ready for consumption.
- Misalignment in business terminology
- Catalogs collect unprocessed physical metadata from various data sources. This compilation of metadata generates a chaotic environment. To establish control, organizations incorporate a business glossary layer that standardizes shared terms, definitions, and classifications. This business glossary offers a certain level of comprehension regarding the physical data. Nevertheless, the interpretation of physical metadata varies within the context of the business process in which it is employed; furthermore, data frequently undergoes transformations throughout its lifecycle. Consequently, the misalignment between business terms and technical metadata can pose significant challenges.
- Treating metadata as data domain itself
- In many organizations, the individuals who own the domain data are also responsible for the metadata of that particular data domain. However, it is frequently observed that these owners are not furnished with the necessary guidelines for naming standards, composing a comprehensive definition, establishing criteria for data categorization and classification, and other related tasks. Furthermore, metadata is not part of their job responsibilities/ OKRs to be accomplished.
- The data domain teams possess a profound understanding of the business processes and context within their respective domains. Nevertheless, they lack a comprehensive perspective of metadata at the enterprise level, which hinders their ability to associate the relevant assets with the business processes.
- Data set definition
- Defining and identifying the granularity of data products poses a nontrivial challenge. Numerous organizations lack clarity in determining the specific data that will be accessible as a dataset, whether it originates from the raw zone, curated zone, or the primary data source..
- The ownership of published datasets raises the question of who is responsible for the data. Specifically, it prompts an inquiry into whether the actual source systems or systems of reference hold the ownership rights. Additionally, the scenario of having multiple sources vying for the same dataset or data product further complicates the matter.
- The absence of contextual information regarding the dataset’s content and the lack of a clear definition for the collection of data pose challenges in comprehending and effectively utilizing datasets.
- Data culture and maturity
- Organizations that possess the appropriate mindset, skills, and capabilities can effectively utilize data catalogs to promote data literacy, collaboration, experimentation, and learning.
- Uncoordinated efforts between data governance and data quality teams can result in a loss of confidence and mistrust in data catalogs. While catalogs are useful for harvesting metadata and making it available for discovery, they do not govern the data. Mobilizing governance councils and committees requires additional time, budget, and management involvement.
- A lack of coordination between data governance and data privacy and security teams can lead to issues with accessing unauthorized or incorrect data.
- It is important to note that IT teams are typically responsible for purchasing catalogs, and vendors may prioritize developing features that support IT teams over the actual consumers who use the metadata for their daily activities.
**Note: Without proper data governance in data catalogs, businesses will incur increasing costs for data analytics and data handling and management.
- Time to value
- The process of establishing a data catalog can take several months, however, achieving successful adoption may take years. This is due to the need for integration with the data consumption layer and the incorporation of metadata management standards and validation.
- Without proper integration and metadata management , the physical metadata loaded into the catalog is of little use to analysts.
- Data leaders often prioritize the number of data sources harvested or assets cataloged, rather than the extent of process change or the value generated. To provide real value, it is crucial to focus on the latter.
Ready to learn more about implementing a data catalog? Schedule a demo to learn more about EIIG’s data catalog capabilities.
About the Author: Ram Pratti is the Chief Evangelist at Orion Governance, Inc. Connect with Ram on LinkedIn.
recent posts

How Orion’s Enterprise Information Intelligence Graph (EIIG) Transforms Python and Java into Trusted Data for AI
Many data governance platforms claim support for Python and Java, but their capabilities often end with cataloging code repositories [...]

How Orion Governance’s Enterprise Information Intelligence Graph Enhances AI Explainability
As organizations accelerate AI adoption, a critical barrier limits trust in AI outcomes: the inability to clearly track where [...]
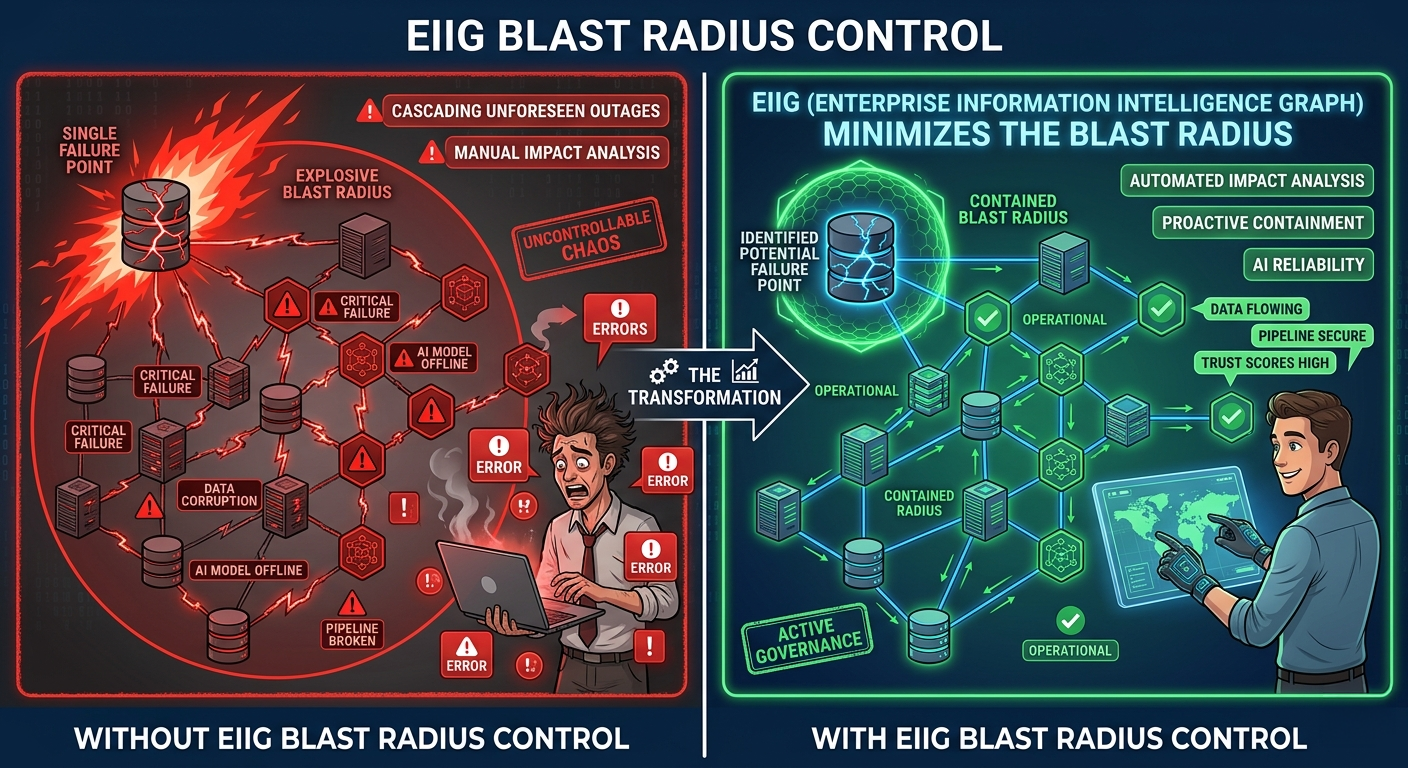
How Orion Governance’s EIIG Enables Blast Radius Calculation to Strengthen Data and AI Governance
In modern enterprises, data ecosystems have become deeply interconnected across cloud platforms, AI pipelines, analytics tools, legacy systems, and [...]
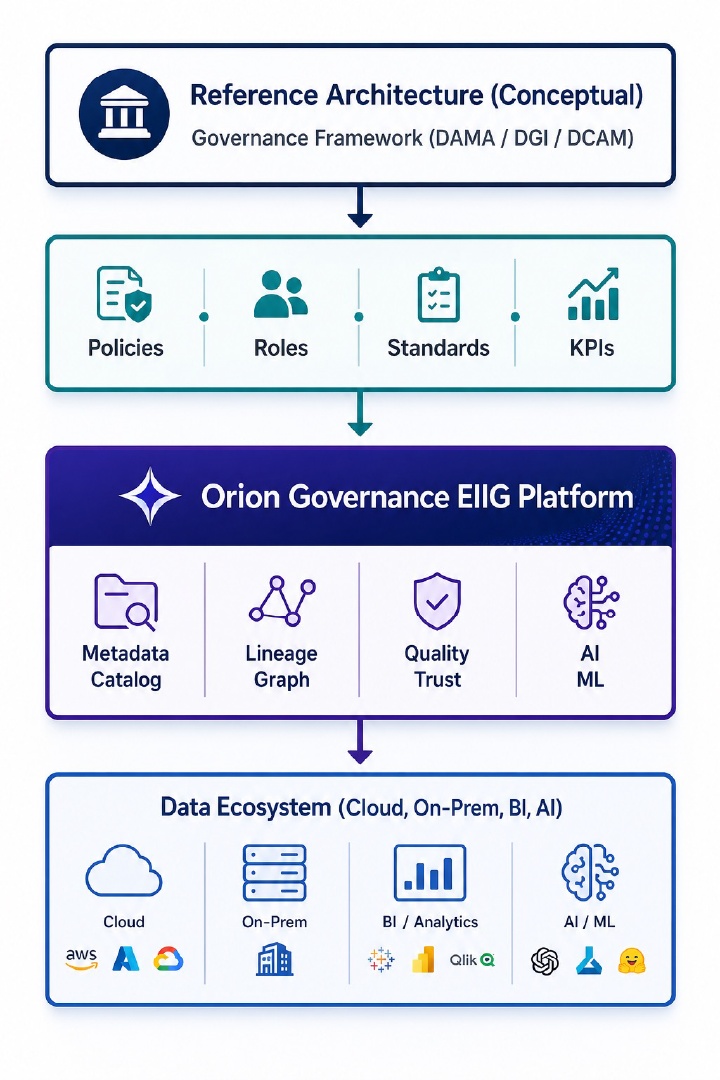
How to Leverage Orion Governance Enterprise Information Intelligence Graph to Implement Data Governance Framework
To use Orion Governance Enterprise Information Intelligence Graph (EIIG) effectively, you shouldn’t treat it as “just a tool.” It [...]

Orion Governance Enterprise Information Intelligence Graph Data Quality Baseline Report
A Data Quality (DQ) Baseline Report acts as the "health check" of your data before any remediation begins. In [...]

From Data Lineage to Enterprise Intelligence Fabric
Orion Governance’s Enterprise Information Intelligence Graph (EIIG) offers the definitive data lineage solution: automated, comprehensive, granular, multi-layered, and collaborative. [...]
