
According to Gartner, “A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata assets to support the design, deployment and utilization of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.”
Data fabric, in other words, starts with metadata assets. Therefore, what metadata to ingest and how to ingest is essential to the success of a data fabric.
Comprehensive coverage of technologies
There are different ways to categorize metadata. But in a nutshell, there are two types. One type has to do with the design and is often called technical or structural metadata. This kind of metadata is definitional, dealing with schema, table and column information, and data quality profiles etc. The other type is operational metadata. It is descriptive, covering metadata about business operations, including data transformation, lineage, ETL jobs, codes, data volume, usage, business glossary, and collaborative/social media information such as user ratings.
In order for data fabric to be useful and meaningful, it needs to be capable of ingesting both technical and operational metadata supporting a comprehensive range of technologies. In many cases, partial support does not help.
For example, in the mainframe environment, if you don’t cover LP/I and COBOL, your metadata analytics will yield only inaccurate and misleading results, not true insight. Here is another example, if you claim to support Teradata, but are unable to parse scripts written in Perl in that environment, your claim is hollow, or at least half empty.
A final example is, in a modernization/cloud migration project, the customer needs detailed understanding of the whole data supply chain, from legacy infrastructure, data lake, to the cloud-based technologies. Without ingesting all key metadata from sources such as databases, ETL tools, programming languages, business glossaries, and BI reports, the planning and execution of the migration project will be almost impossible.
Automation is the key
One of the trademarks of data fabric is to minimize human intervention. This means automation from the start, or from the ingestion of metadata. Orion’s Enterprise Information Intelligence Graph (EIIG) is the most automated self-defined data fabric platform in the market. In the context of meta ingestion, EIIG automates the process of defining, uploading, and ingesting to create a comprehensive map of an enterprise’s information assets. Automatic scanners and connectors enable ingestion of 60+ technologies without any manual effort.
This automated process includes features to simplify and enable active metadata. For example, there is integration with popular platforms such as ServiceNow and Jira so that you can understand, monitor, and manage issues and defects. Annotations in the code are already incorporated and provide information about the assets. All these require zero coding.
Once you use EIIG to ingest the metadata quickly and effectively, you have built a foundation to gain insights into your information assets.
Please give EIIG a try and see how you can get value out of your data in a matter of weeks instead of months and years.
About the author: Niu Bai, Ph.D. is the Head of Global Business Development and Partnerships at Orion Governance, Inc.
recent posts
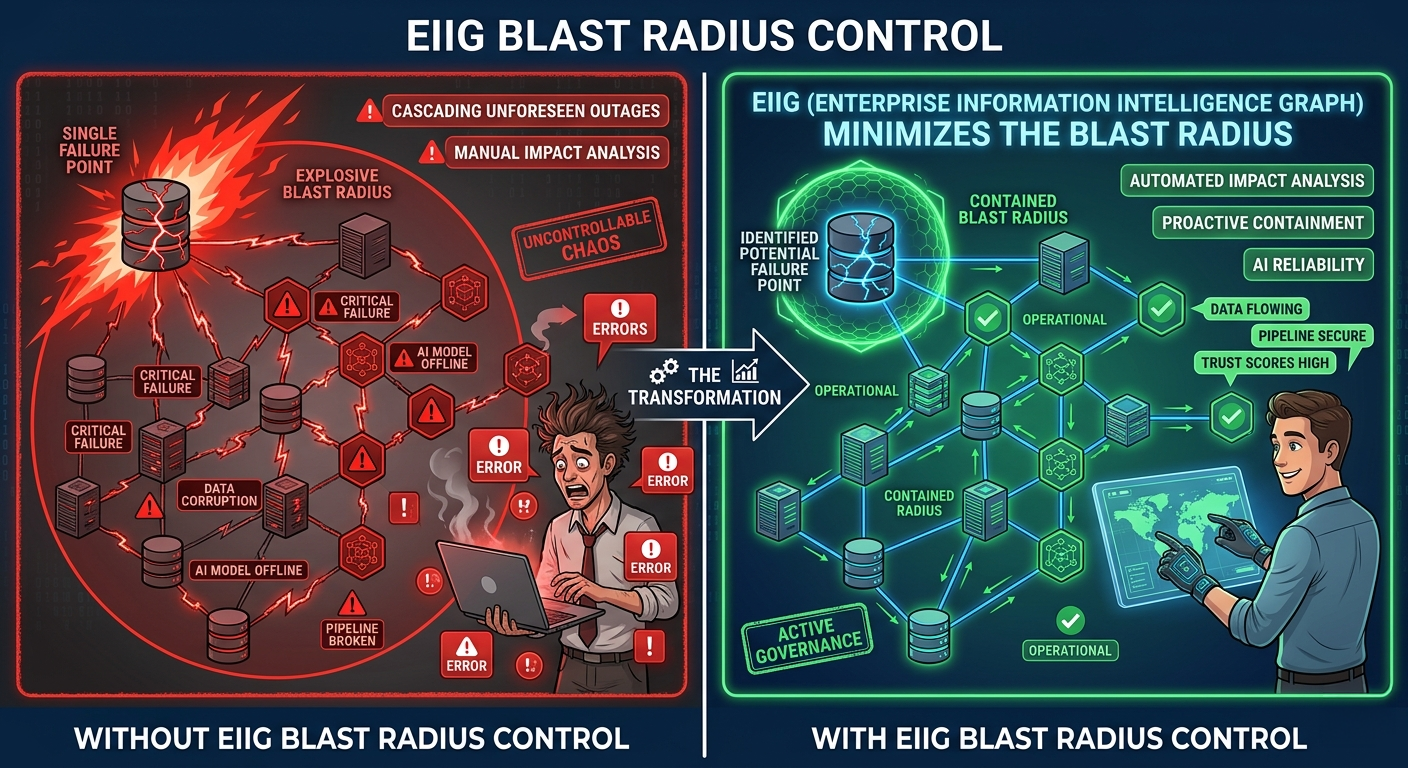
How Orion Governance’s EIIG Enables Blast Radius Calculation to Strengthen Data and AI Governance
In modern enterprises, data ecosystems have become deeply interconnected across cloud platforms, AI pipelines, analytics tools, legacy systems, and [...]
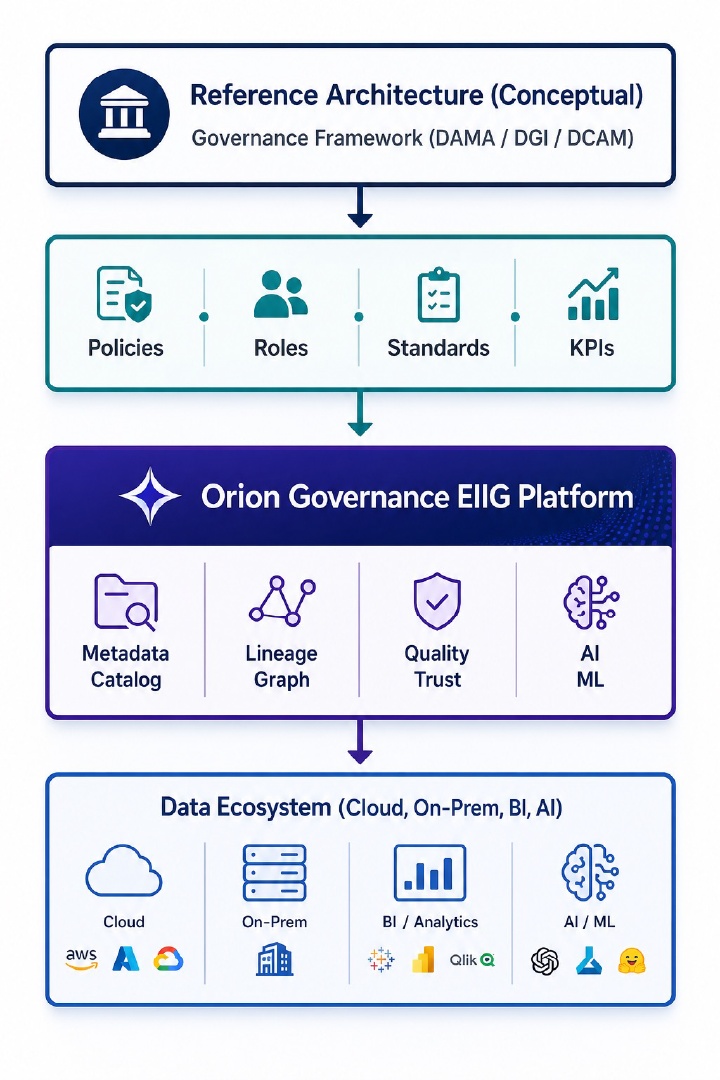
How to Leverage Orion Governance Enterprise Information Intelligence Graph to Implement Data Governance Framework
To use Orion Governance Enterprise Information Intelligence Graph (EIIG) effectively, you shouldn’t treat it as “just a tool.” It [...]

Orion Governance Enterprise Information Intelligence Graph Data Quality Baseline Report
A Data Quality (DQ) Baseline Report acts as the "health check" of your data before any remediation begins. In [...]

From Data Lineage to Enterprise Intelligence Fabric
Orion Governance’s Enterprise Information Intelligence Graph (EIIG) offers the definitive data lineage solution: automated, comprehensive, granular, multi-layered, and collaborative. [...]

The Benefits of Using Orion Enterprise Information Intelligence Graph to Accelerate Cloud Migration/ Modernization
Cloud migrations are often framed as a technical exercise — move systems, modernize platforms, decommission legacy tools. But the [...]

Is Duplicate Data Silently Draining Your IT Budget?
Data redundancy isn't just a storage issue—it's a governance, risk, and cost challenge. At Orion Governance, the Enterprise Information [...]
