

More and more enterprises are adopting data catalogs to be more data-driven and to provide more self-service. However, not all data catalogs are created equal. Organizations need deep cataloging when they build a data fabric. This is because, at its core, a data fabric is about eliminating human intervention as much as possible. Without deep cataloging, augmented (AI-based) orchestration is not feasible, and a data fabric cannot thus be weaved.
Deep cataloging should have three major capabilities:
Covering all types of technologies
A data fabric provides a holistic view of data across the IT landscape. In this design, a data catalog needs to cover all types of technologies. It must include not only databases, data warehouses, and data lakes, but also cloud resources, programing languages, APIs, ETL tools, and BI reporting products. Without this foundational capability, a data catalog is partial and passive. For example, if a catalog can handle only databases and BI reporting, it will need human intervention in cases like change management that may involve programming languages such as Java or Perl. This requirement of human efforts undermines the very concept of data fabric.
Applying quality and business policies and rules
Another trait of deep cataloging is its capability of automatically applying quality and business policies/rules. An enterprise data catalog should incorporate quality metrics and visualize quality scores at every step of the data supply chain. When you have thorough understanding of quality behind the assets, you can reduce costs by eliminating duplicated or unused data. In addition, together with data lineage, this dynamic understanding of data quality establishes trust. As a result, self-service becomes much more efficient.
What more, deep cataloging provides automatic mapping of assets to terms and associating business policies/rules. By doing so, organizations can enhance proactive data governance and enable better decision making. We can use a map analogy here:
A map with street names and addresses is useful but not sufficient. You want to know traffic information, what are the traffic rules and what happens when rules are violated etc. Armed with such insights, authorities can make, change, and enforce traffic rules proactively; and travelers can find the best time and best route to get to a destination
By the same token, using deep cataloging, enterprises understand how data flows from source to target through various systems; how reliable their systems are; what policies and rules are in place for what assets; and how these policies and rules are enforced. With this knowledge, they can make sounder decisions based on facts.

Enabling collaboration and meeting needs of all types of users
One of the key benefits and capabilities of deep cataloging is a platform for collaboration and a single model with multiple use cases.
As part of an enterprise information intelligence graph, this data catalog facilitates communications between business and technical users. Powered by open APIs and integration with popular third-party platforms such as ServiceNow, this catalog bridges the gap between IT and business users.
No matter how complicated systems are, data flow is transparent for everybody to see in this data catalog. Enterprise segments/user personas see their view and how it relates to other views built upon the same model. Everybody can translate the information in his/her own and more meaningful way. For example, data stewards can set up policies and rules and exert control; and compliance officers can easily find the PII information and enforce rules and policies according to regulations. They can conduct all these activities independently, true instances of shadow IT.
A key difference between an active data catalog and a passive one is the ability to activate metadata. Embedded impact analysis is one of the features of an active data catalog or deep cataloging. This analysis shows the cause-and-effect, visualizing the consequences of any proposed changes. Cloud architect can use this analysis to make and execute data migration plans. Application developers can leverage it to do testing and prioritize resources.
As we can see that deep cataloging does not discriminate; all personas, business or technical, can benefit from it.
To sum up, deep cataloging, coupled with automation is an essential to building a data fabric. With broad technology coverage, automation, application of quality and other types of rules and policies, and versatility for all user personas, it enables enterprises to get the most value out of their data in a very short time.
About the author: Niu Bai, Ph.D. is the Head of Global Business Development and Partnerships at Orion Governance, Inc.
recent posts

How Orion’s Enterprise Information Intelligence Graph (EIIG) Transforms Python and Java into Trusted Data for AI
Many data governance platforms claim support for Python and Java, but their capabilities often end with cataloging code repositories [...]

How Orion Governance’s Enterprise Information Intelligence Graph Enhances AI Explainability
As organizations accelerate AI adoption, a critical barrier limits trust in AI outcomes: the inability to clearly track where [...]
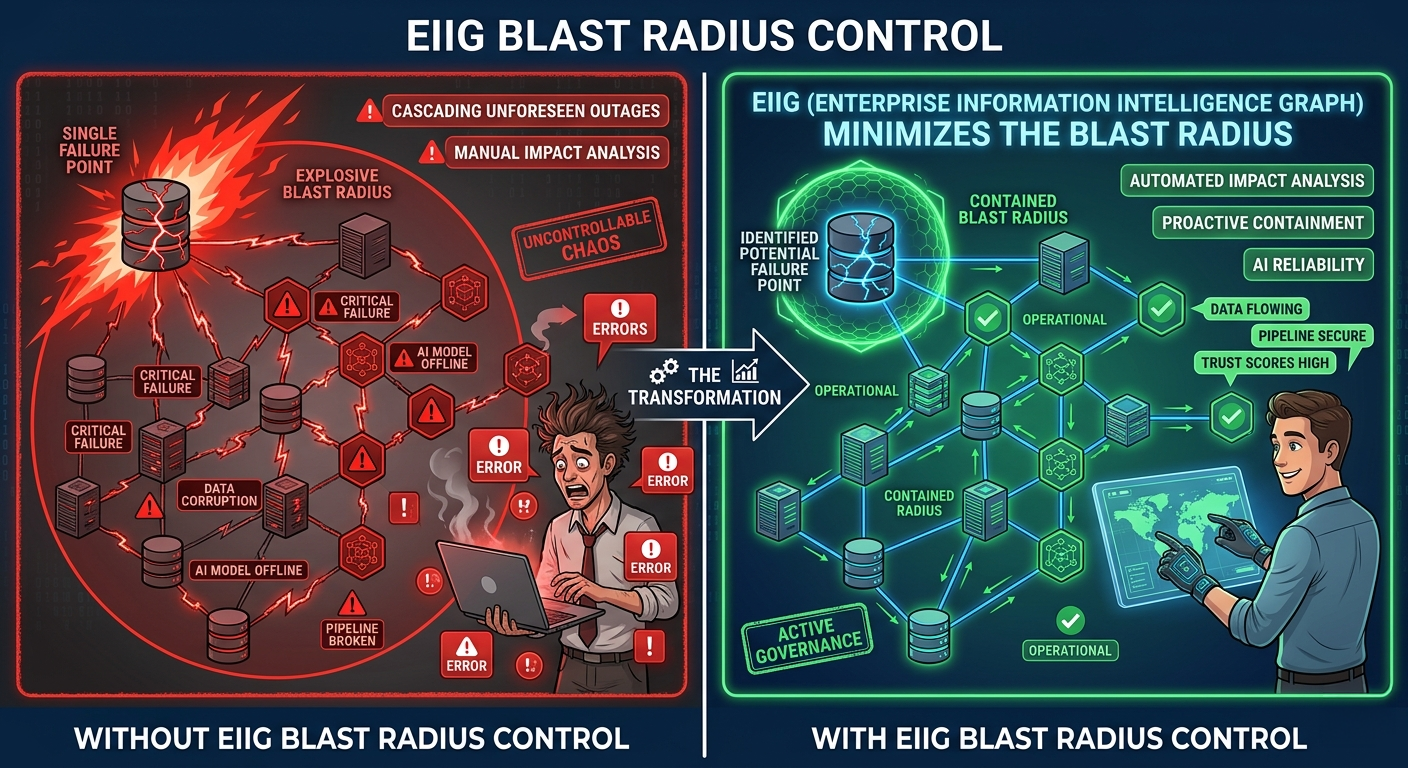
How Orion Governance’s EIIG Enables Blast Radius Calculation to Strengthen Data and AI Governance
In modern enterprises, data ecosystems have become deeply interconnected across cloud platforms, AI pipelines, analytics tools, legacy systems, and [...]
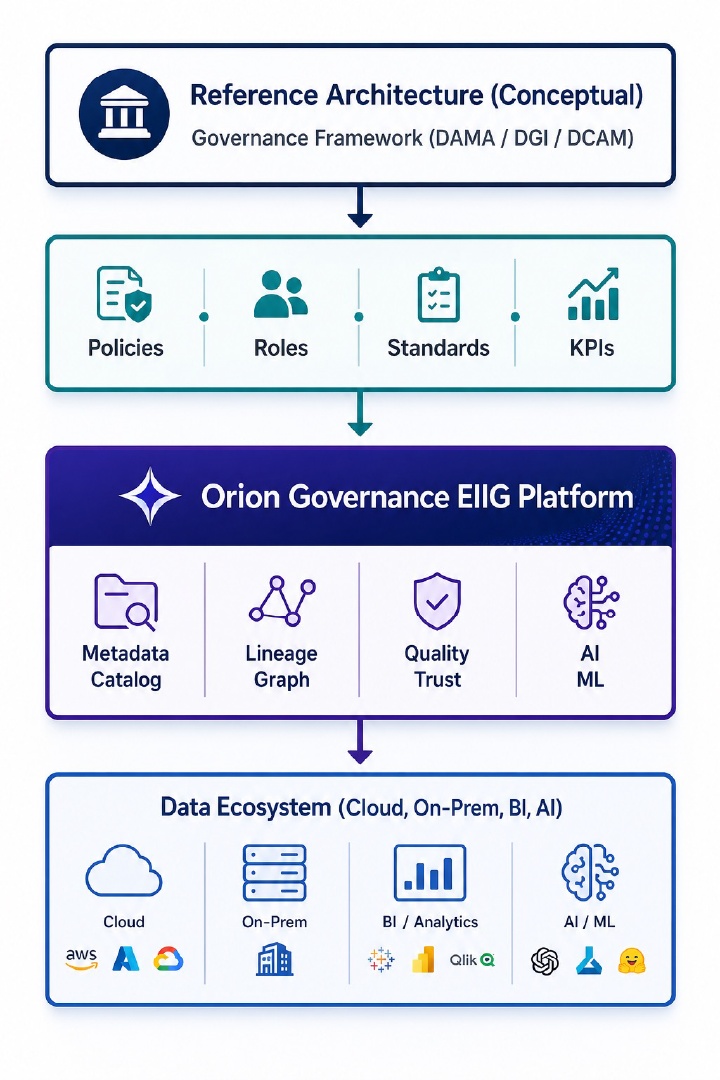
How to Leverage Orion Governance Enterprise Information Intelligence Graph to Implement Data Governance Framework
To use Orion Governance Enterprise Information Intelligence Graph (EIIG) effectively, you shouldn’t treat it as “just a tool.” It [...]

Orion Governance Enterprise Information Intelligence Graph Data Quality Baseline Report
A Data Quality (DQ) Baseline Report acts as the "health check" of your data before any remediation begins. In [...]

From Data Lineage to Enterprise Intelligence Fabric
Orion Governance’s Enterprise Information Intelligence Graph (EIIG) offers the definitive data lineage solution: automated, comprehensive, granular, multi-layered, and collaborative. [...]
